
Engineering With Intent: Why Build Is Not the Goal
March 4, 2026

I’ve watched this scene play out more times than I’d like to admit.
A team grinds for weeks (sometimes months), fights through scope changes, navigates “quick” dependencies that aren’t quick, and ships. There’s a release announcement. Somebody posts the Jira burn-down screenshot. Leadership gets a demo. There’s that little hit of relief, the “we got it out the door” exhale.
And then… nothing.
Adoption doesn’t move. Customers don’t behave differently. The operational teams keep doing what they were doing before. The business metric that justified the work stays flat. Sometimes it even gets worse and it’s hard to define why (it’s because the organization just added another thing to maintain).
The cynical interpretation is that people don’t care.
The more accurate interpretation is harsher: we shipped an output, not an outcome.
Here’s the line I want you to keep in your pocket:
Shipping is a hypothesis, not a finish line.

If you want your engineering organization (and especially your data/AI investments) to produce durable value, the discipline isn’t “ship more.” The discipline is: define what should change, measure it, and build only what credibly drives that change.
That is what I mean by engineering with intent.
The failure epidemic (and why the “build-first” crowd should be nervous)
The failure statistics in modern technology work are devastating. And I don’t mean “a few projects go sideways.” I mean systemic failure at an industrial scale.
A few datapoints (and I’ll keep this tight, because you don’t need a spreadsheet to feel the weight of it):
- Only ~30% of large-scale tech programs meet expectations for time, budget, and scope (with no improvement over a decade).
- ~95% of enterprise AI projects deliver zero measurable bottom-line impact.
- Only ~1 in 200 IT projects delivers intended benefits on time and on budget.
- ~70% of digital transformations fail, and culture, not technology, is the primary obstacle.
Read that again and let it land.
If your organization is proudly “moving fast” while operating inside these base rates, you’re not moving fast. You’re moving blind.
The burden of proof has shifted. The default assumption should no longer be “this initiative will work.” The default assumption should be: most initiatives will not produce the value we think they will unless we build differently.
Which brings us to the trap.
The build trap: when output becomes the objective
Most engineering orgs don’t intend to worship output. It happens gradually, then all at once, and now it’s your culture.
It shows up in familiar forms:
- Deployments as vanity milestones (“We shipped!”)
- Models without measurable outcomes (“We have an AI pilot!”)
- Dashboards without decisions (“We delivered the reporting!”)
- Roadmaps as comfort blankets (“We have a plan!”)
At the center is a quiet substitution:
We replace “value delivered” with “work completed.”
That substitution is incredibly tempting because outputs are visible and outcomes are messy.
Outputs:
- Can be counted
- Can be demoed
- Can be placed on a timeline
- Can be celebrated without argument
Outcomes:
- Require agreement on what success means
- Require instrumentation and measurement discipline
- Require time, feedback loops, and sometimes uncomfortable truth
- Force tradeoffs and focus
So we drift. And eventually we arrive at a system where the organization is genuinely optimized for shipping… not for impact.
Melissa Perri calls this the build trap: organizations measure success by what they ship, not what changes.
Josh Seiden gives the cleanest definition of what we should be pursuing instead: an outcome is “a change in human behavior that creates value.”
Marty Cagan draws the line between feature teams and empowered teams: empowered teams are given problems to solve, not features to build.
Notice what all three frameworks have in common:
No one is arguing for less engineering.
They are arguing for engineering that knows what it is for.
Because without that, you get the modern feature factory: high throughput, low conversion into proven value.
Why smart organizations stay stuck (it’s not just “bad leadership”)
If you’ve ever tried to pull an org out of this trap, you’ve probably experienced the pushback:
- “We don’t have time for all that planning.”
- “Let’s just build something and iterate.”
- “We’ll measure later.”
- “The business needs results now.”
Here’s what matters: this pushback isn’t random or malicious. It happens because we’re human. It’s a feature, not a bug.
Behavioral science explains why build-first cultures persist, even when the data says they’re losing.
The planning fallacy: the inside view addiction
We systematically underestimate the time, cost, and risk of complex work because we take the “inside view,” we focus on the specifics of this initiative instead of the base rates of similar initiatives.
And organizations actively reward confident over-optimism because it sounds like leadership.
Sunk cost: zombie initiatives are socially protected
Once you’ve invested budget, headcount, and political capital, it becomes emotionally and organizationally expensive to admit you were wrong. So projects continue long past the point where evidence says they should pivot, or stop.
Action bias: motion feels like progress
In most organizations, the visible signal of productivity is “stuff shipped.” Stepping back to define outcomes, instrument measurement, and set decision gates can look like delay, especially to stakeholders who live in PowerPoint timelines.
Goodhart’s Law: metrics get gamed
Even when organizations do measure, they often measure the wrong things (or measure the right thing in the wrong way). When a measure becomes a target, people optimize the number instead of the reality. That’s how you end up with velocity theater, trivial work slicing, and meaningless deployment frequency.
So if you’re the person advocating for intent, clarity, measurement, decision gates, you can feel like you’re swimming upstream.
You are.
But here’s the point: the upstream swim is where the leverage is.
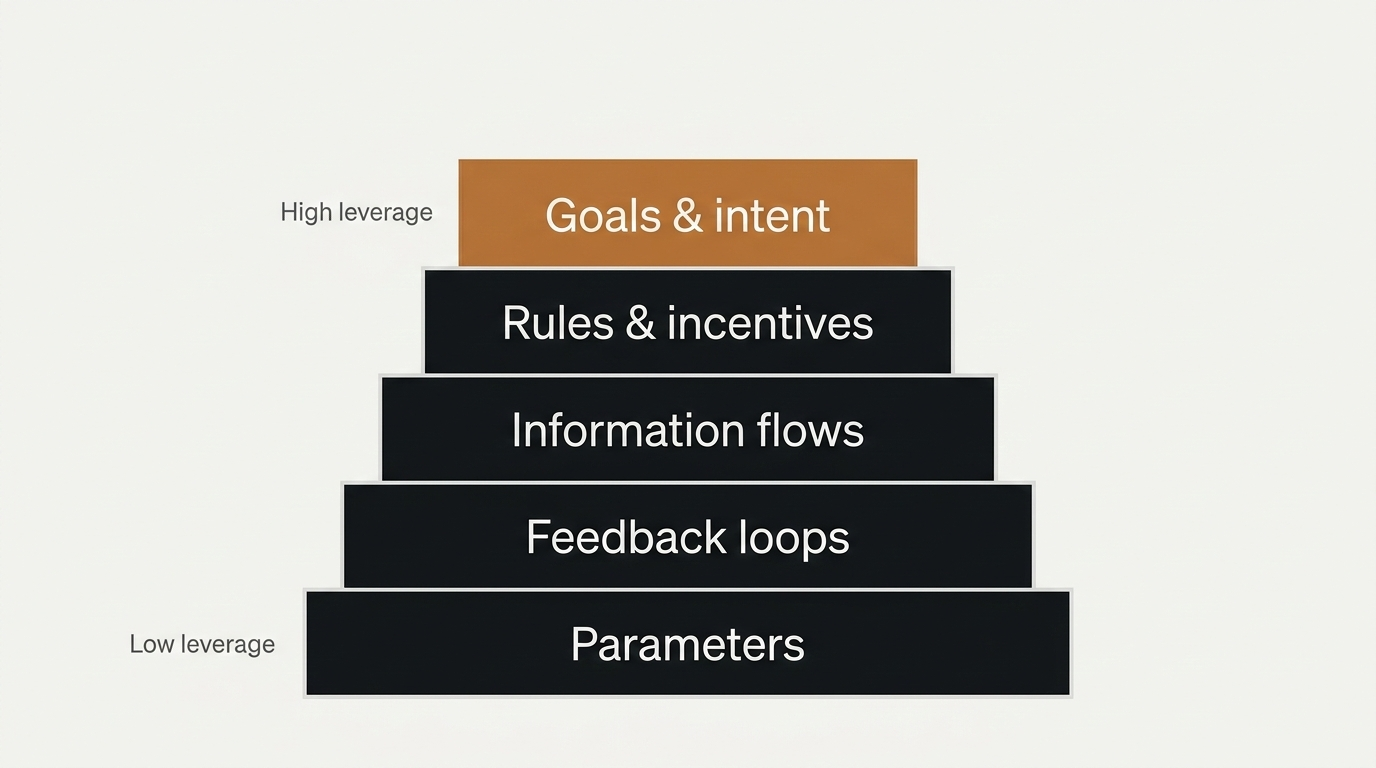
Systems thinking: where leverage actually lives
Donella Meadows’ leverage points framework is the most useful intellectual anchor I’ve found for this problem because it explains something that feels obvious in hindsight:
Most organizational effort goes into low-leverage intervention.
We love tweaking parameters:
- More headcount
- Different tools
- Another backlog grooming session
- More dashboards
- Another layer of process
These live in the lower-leverage layers of a system.
Meadows ranks leverage points from least to most powerful. At the top, highest leverage, are things like goals, rules, and information flows.
Her blunt observation is that the vast majority of attention goes to parameters, where leverage is weakest.
This maps directly to engineering organizations that “make the build the goal.” They fight about tooling, architecture patterns, sprint rituals, and whether to use framework X or Y, while never getting alignment on:
- What friction are we reducing?
- What behavior must change?
- What metric should move?
- How will we know if it did?
If you want to escape the build trap, don’t start by optimizing the factory.
You have to start by changing the intent of the factory.
A practical framework: Engineering With Intent
I’m not interested in philosophy that can’t survive contact with a backlog.
So here is the framework I use to connect engineering work to measurable value. It’s synthesized from a lot of research across product strategy, systems thinking, and delivery discipline, but the point is simple: it’s usable. It will make your work-life feel easier, more sensible.
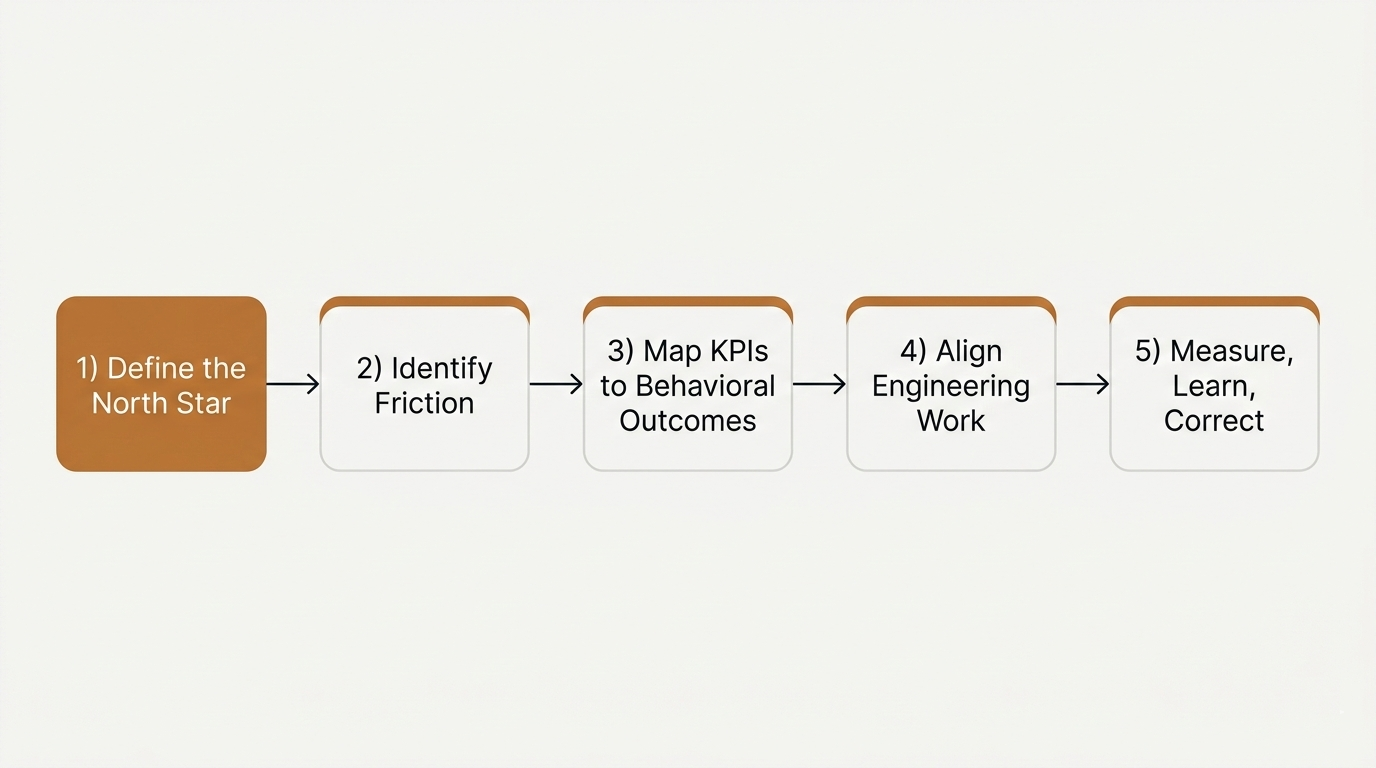
The flow
Define the North Star → Identify Friction → Map KPIs to Behavioral Outcomes → Align Engineering Work → Measure, Learn, Correct.
And here’s the connective tissue that most organizations skip:
Friction → behavioral change → KPI → North Star.
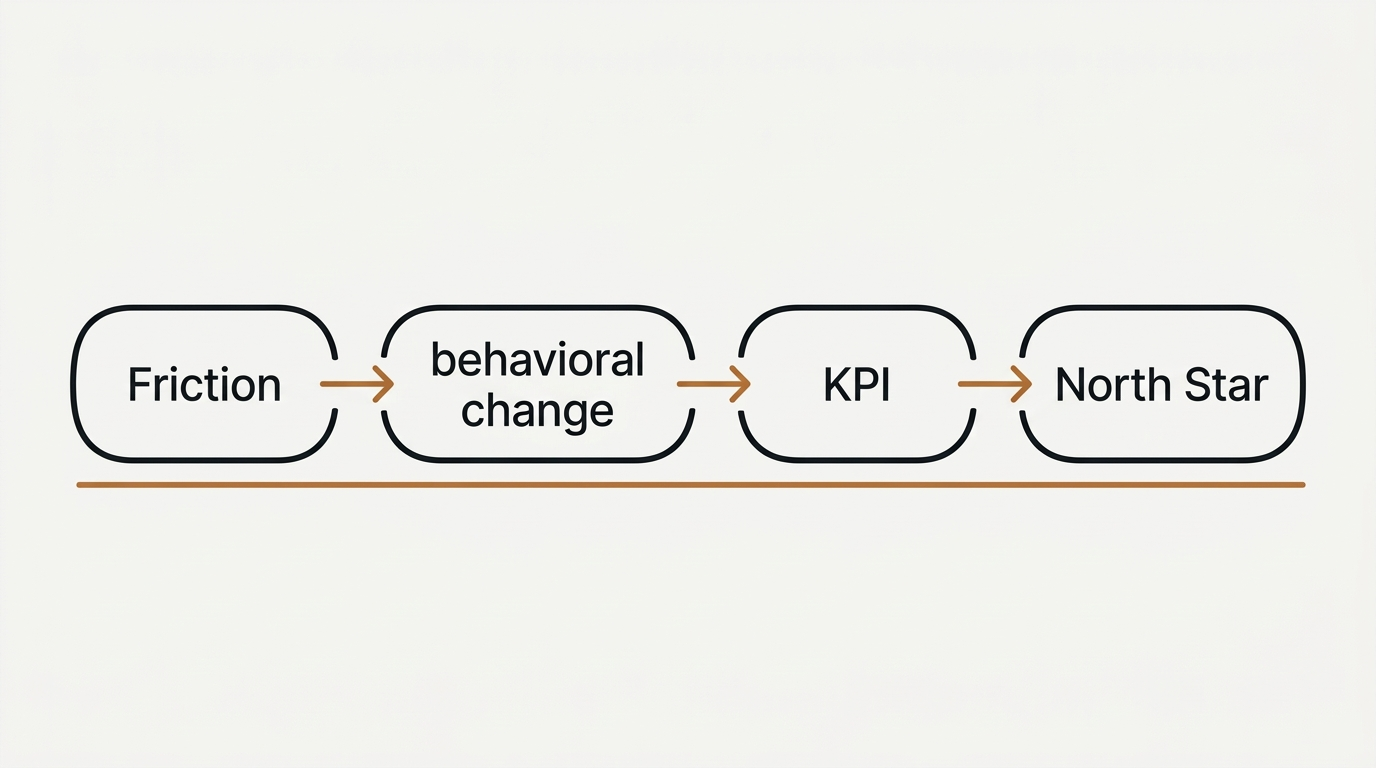
You don’t build “features.” You build interventions that reduce friction, change behavior, move a KPI, and ladder into the objective.
Let’s walk it.
Phase 1: Define the North Star (before you build anything)
Before engineering work begins, establish the organization’s north star metric, the single measure that best captures customer value and business success.
My test is brutally practical:
If this metric improves, does the business demonstrably succeed?
If the answer is “not necessarily,” it’s not your north star. It might be a useful KPI. But it can’t be the organizing principle.
A north star isn’t “we shipped AI.”
A north star isn’t “we launched a new dashboard.”
A north star is a value signal that can anchor prioritization when things get loud.
Note: my upcoming book will go deep on north star selection patterns by business model, anti-patterns, and the difference between “north star” and “north star theater.” For now, just keep the test.
Phase 2: Identify friction points (not solutions)
This is where most teams fail immediately: they jump from “goal” to “build.”
Instead, identify the friction, the constraint in the system that limits value delivery.
Theory of Constraints gives the correct mental model: every system has a constraint. If you optimize everything except the constraint, you produce local improvements that don’t change global throughput.
In practice, this means:
- Map the value stream (where value is created vs where it stalls)
- Find the “stuck point” that drives the most downstream pain
- Treat that as the starting point, not a feature request
Also, Goldratt’s warning matters here: once constraints shift, the old rules become policy constraints that keep the system stuck.
Many organizations are limited more by their inherited rules than by their actual technical capacity.
Phase 3: Map KPIs to behavioral outcomes
This is the bridge that turns strategy into something teams can actually execute.
Remember Seiden’s definition: outcomes are changes in human behavior that creates value.
So for each friction point, define:
- The behavioral change that resolves it
- The KPI(s) that indicate that change is happening
- How those KPIs ladder to the north star
This is where many orgs get lazy. They go straight from “north star” to “build this initiative,” without articulating the behavior change that actually moves the metric.
And because the behavior isn’t explicit, measurement becomes fuzzy. Which means accountability becomes political. Which means everything devolves back into output.
Guardrail: Goodhart is always waiting
If you pick one metric and worship it, people will game it. The solution is not “no metrics.” The solution is a balanced metric strategy: if you measure speed, measure quality; if you measure output, measure collaboration; if you measure volume, measure outcomes.
Phase 4: Align engineering work to outcomes
Now, and only now, do we talk about what to build.
Every initiative should trace back to:
- a friction point
- a measurable behavioral outcome
- a KPI chain
- and ultimately the north star
Two practical forcing functions I use constantly:
“Problems, not features.”
If a team is handed a feature list, they’re being set up as a factory. If they’re given a problem with measurable outcomes, they can act like engineers.
The press release test.
If you can’t explain the initiative in plain language, what problem it solves and why anyone should care, you’re not ready to build.
Tie this to quarterly execution via OKRs if you want structure, but the deeper point is alignment: the work is accountable to measurable change.
Phase 5: Measure, learn, correct (with explicit decision points)
Most organizations treat retrospectives as the “learning mechanism” and assume that’s enough.
It isn’t.
You need a review cadence that answers one question:
Is our engineering work moving the KPIs that drive the north star?
And every meaningful initiative needs built-in decision points, criteria for continuing, pivoting, or stopping.
This is the antidote to:
- the planning fallacy (you recalibrate using reality)
- sunk cost (you pre-commit to stopping criteria)
- Goodhart (you balance metrics and watch for gaming)
Without decision points, “measure later” becomes “never measure,” and the system quietly returns to shipping as the definition of success.
A concrete example thread (so this doesn’t stay theoretical)
Let’s use a scenario that’s painfully common:
A company invests in a new AI assistant to “reduce customer support cost.”
Output framing: “Launch an AI chatbot.”
Intent framing: “Reduce the friction that causes repeat contacts and long handle time, without degrading customer trust.”
Now apply the framework:
North Star
Choose a north star that reflects customer value + business health. Maybe it’s something like retention or successful task completion, depending on the business. The exact metric varies, but the test stays the same: if it improves, the business succeeds.
Friction
Don’t start with “build a bot.” Start with where value is leaking:
- Customers repeat themselves across channels
- Agents can’t find the right information fast enough
- The top 10 drivers of contact volume are preventable but unaddressed
Behavioral outcome
What should people do differently?
- Customers self-serve for specific tasks successfully
- Agents resolve faster with fewer transfers
- Fewer repeat contacts within 7 days
KPI chain (with guardrails)
- Leading indicators: containment rate for specific intents, time-to-answer, agent search success rate
- Lagging indicators: repeat contact rate, CSAT, cost per resolution
- Guardrails: escalation quality, complaint rates, trust metrics
Engineering work
Now you can decide what to build:
- Instrumentation to identify top friction intents
- Knowledge retrieval improvements (not “a chatbot,” but “faster correct answers”)
- Workflow embedding so AI isn’t a side tool
- Content governance so outputs stay accurate
Measure + decision points
Pre-commit:
- If repeat contact rate doesn’t move by X within Y weeks, pivot approach
- If CSAT drops below guardrail, stop and fix trust before scaling
That’s engineering with intent.
Notice what didn’t happen:
- We didn’t start with a tool.
- We didn’t declare victory at launch.
- We didn’t confuse “pilot shipped” with “value realized.”
The Monday morning mini-playbook (30–60 minutes)
If you want to start applying this immediately, here’s a simple workshop you can run this week with your team and a stakeholder.
Pick one active initiative. Just one.

Step 1 (10 minutes): Name the friction
Ask:
- What friction are we reducing?
- Where does value stall today?
- What constraint is most limiting throughput?
If you can’t answer in one sentence, you don’t have clarity yet.
Step 2 (10 minutes): Define the behavioral change
Ask:
- What will people do differently if this works?
- Who is the “actor” whose behavior changes, customer, agent, analyst, ops team, sales rep?
Write it in plain language.
Step 3 (15 minutes): Build the KPI chain
Draw this on a whiteboard:
Friction → Behavior change → KPI(s) → North Star
Pick:
- 1–2 leading indicators (things you can influence soon)
- 1–2 lagging indicators (the business impact)
- 1–2 guardrails (quality/trust/stability)
Step 4 (10 minutes): Set a decision gate
Agree on:
- What result means “continue / scale”
- What result means “pivot”
- What result means “stop”
Write it down. Put a date on it.
Step 5 (5 minutes): Align the build
Only now ask: what work actually moves the leading indicators?
If the proposed build doesn’t credibly move the chain, it doesn’t belong on the roadmap.
That’s the whole playbook.
Don’t buy into process theater. What you want is leverage.
Closing (and why I’m working on the book)
If this argument feels obvious, that’s the point.
Most dysfunction in engineering organizations isn’t caused by a lack of intelligence or capability. It stems from a lack of discipline around intent.
The research is clear: the majority of tech initiatives will succeed in getting built and still fail to deliver the intended value, and it’s because organizations confuse building with outcomes.
Engineering with intent is not slower engineering.
It’s engineering that knows what it is for.
This essay gives you the spine:
- Start with friction
- Define the behavior change
- Map the KPI chain
- Build only what moves it
- Measure with decision points
The book will go deeper on the parts that separate a good idea from an operating system:
- A rigorous north star selection method (and anti-patterns)
- A repeatable friction audit (constraint + value stream + policy constraints)
- KPI chain design that resists Goodhart
- Decision gates that neutralize sunk cost
- An operating model that makes this sustainable quarter after quarter
Think about some of the hottest spaces in tech over the past few years, the metaverse, NFTs, enterprise blockchain applications, Customer Data Platforms, AI-agents everywhere… I’m not saying these weren’t/aren’t important, but there are no silver bullets.
When the goal is durability, Don’t chase hype, Build solutions that outlast it.